Reading Time: 1 minutesWeb scraping in Python
Web scraping in Python
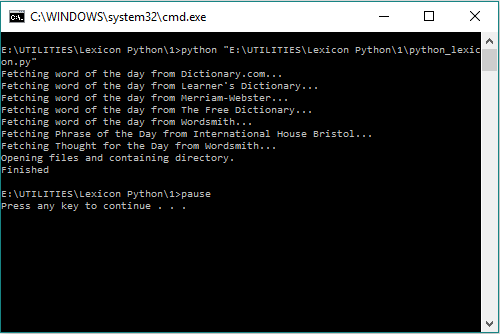
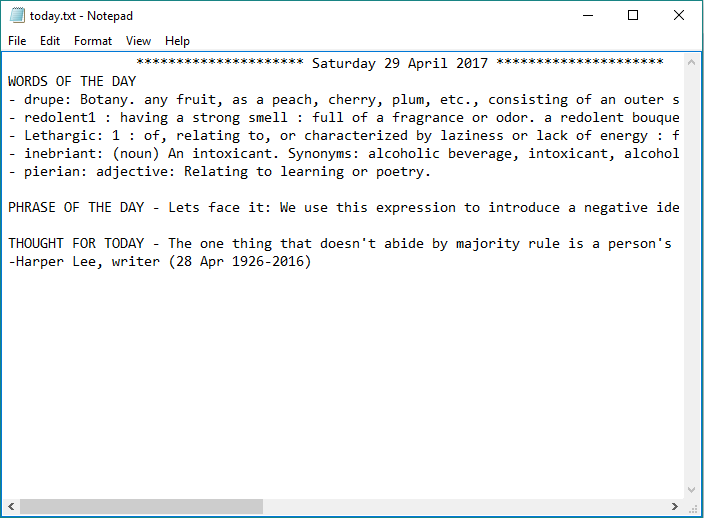
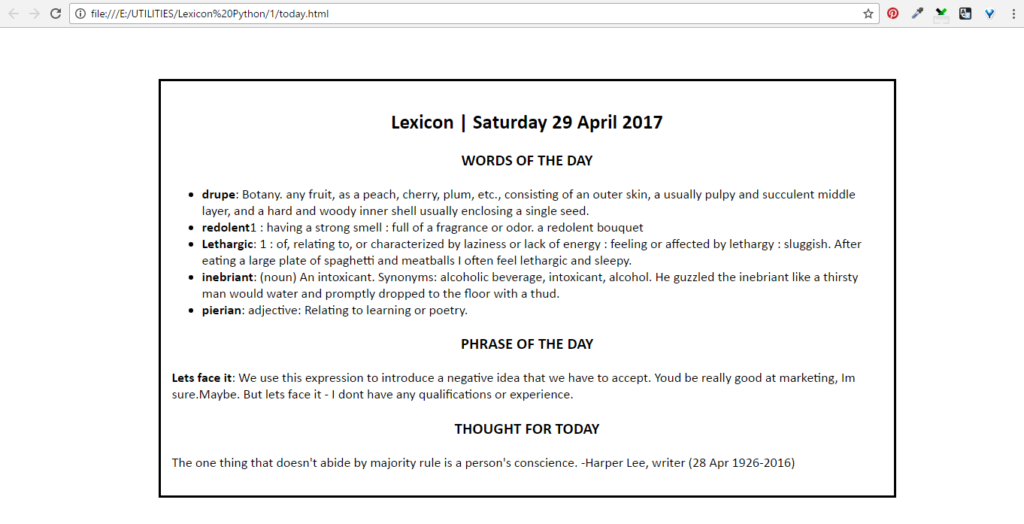
Lexicon: A script that scrapes off word of the day from 5 different websites, along with a phrase of the day and a thought for today. The script writes these words to a text file 'today.txt', an html file 'today.html' and an archive file 'archive.txt'. Once the script finishes, it opens the folder containing these files, and opens these files in notepad and default browser.
Source Code
locationOfYourScript = r'{}'.format(os.path.dirname(os.path.realpath(__file__))) |
os.chdir(locationOfYourScript) |
pathToTXTfile = r'{}\today.txt'.format(os.getcwd()) |
pathToHTMLfile = r'{}\today.html'.format(os.getcwd()) |
pathToArchiveFile = r'{}\archive.txt'.format(os.getcwd()) |
today = datetime.date.today().strftime("%A %d %B %Y") |
with open(pathToTXTfile, 'w') as fileHandler: |
fileHandler.write("\t\t********************* {} *********************".format(today)) |
fileHandler.write("\nWORDS OF THE DAY\n") |
with open(pathToHTMLfile, 'w') as fileHandler: |
fileHandler.write("<!DOCTYPE html>\n<html>\n<head><title>Lexicon {}</title>\n".format(today)) |
fileHandler.write("<style>body {font-family: Calibri; font-size: 18px;} #content {width: 70%; margin-left: 15%; border: 3px solid black; padding: 15px; margin-top: 5%;}</style>\n") |
fileHandler.write("</head>\n\n<body>\n\n<div id = \"content\">\n") |
fileHandler.write("<center><h2>Lexicon | {}</h2></center>\n".format(today)) |
fileHandler.write("<center><h3>WORDS OF THE DAY</h3></center>\n") |
fileHandler.write("<ul>\n") |
print("Fetching word of the day from Dictionary.com...") |
source = requests.get(url) |
matchedObject = re.search(r'Definitions for <strong>(.+?)</strong>[\S\s\n]*?<li class="first"><span>(.+?)</span></li>', source.text) |
word = matchedObject.group(1) |
meaning = matchedObject.group(2) |
cleanedWord = re.sub('<.*?>', '', word) |
cleanedWord = re.sub('&#\d{2,4};', '', cleanedWord) |
cleanedWord = re.sub(' ', ' ', cleanedWord) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
entryForTextFile = "{}: {}".format(cleanedWord, cleanedMeaning) |
entryForHTMLFile = "<strong>{}</strong>: {}".format(cleanedWord, cleanedMeaning) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("- {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<li>{}</li>\n".format(entryForHTMLFile)) |
print("Fetching word of the day from Learner's Dictionary...") |
source = requests.get(url) |
matchedObject = re.search(r'Word of the Day:\s(.*?)\s-[\S\s\n]*?<div class = "midbt"><p>(.*?)</p>[\S\s\n]*?<li class = "vi"><p>(.*?)</p>', source.text) |
word = matchedObject.group(1) |
meaning = matchedObject.group(2) |
usage = matchedObject.group(3) |
cleanedWord = re.sub('<.*?>', '', word) |
cleanedWord = re.sub('&#\d{2,4};', '', cleanedWord) |
cleanedWord = re.sub(' ', ' ', cleanedWord) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
cleanedUsage = re.sub('<.*?>', '', usage) |
cleanedUsage = re.sub('&#\d{2,4};', '', cleanedUsage) |
cleanedUsage = re.sub(' ', ' ', cleanedUsage) |
entryForTextFile = "{}{}. {}".format(cleanedWord, cleanedMeaning, cleanedUsage) |
entryForHTMLFile = "<strong>{}</strong>{}. {}".format(cleanedWord, cleanedMeaning, cleanedUsage) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("- {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<li>{}</li>\n".format(entryForHTMLFile)) |
print("Fetching word of the day from Merriam-Webster...") |
source = requests.get(url) |
matchedObject = re.search(r'<meta property="og:title" content="Word of the Day:\s(\w*)"\s*/>', source.text) |
matchedObject2 = re.search(r'<div class="wod-definition-container">[.\n\s\S]+?<h2>Definition</h2>[.\n\s\S]+?<p>(.+?)</p>[.\n\s\S]+?<h2>Examples</h2>[.\n\s\S]+?(<p>[.\n\s\S]+?</p>)', source.text) |
word = matchedObject.group(1) |
meaning = matchedObject2.group(1) |
example = matchedObject2.group(2) |
cleanedWord = re.sub('<.*?>', '', word) |
cleanedWord = re.sub('&#\d{2,4};', '', cleanedWord) |
cleanedWord = re.sub(' ', ' ', cleanedWord) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
cleanedExample = re.sub('<.*?>', '', example) |
cleanedExample = re.sub('&#\d{2,4};', '', cleanedExample) |
cleanedExample = re.sub(' ', ' ', cleanedExample) |
entryForTextFile = "{}: {}. {}".format(cleanedWord, cleanedMeaning, cleanedExample) |
entryForHTMLFile = "<strong>{}</strong>: {}. {}".format(cleanedWord, cleanedMeaning, cleanedExample) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("- {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<li>{}</li>\n".format(entryForHTMLFile)) |
print("Fetching word of the day from The Free Dictionary...") |
source = requests.get(url) |
matchedObject = re.search(r'[\s\S\n]*?<a href=".*?/(.*?)">Definition</a>:</td>[\n\s]*?<td>(.*?)</td></tr>[\n\s]*?<tr>.*?Synonyms:.*?<td>(.*?)</td></tr>[\n\s]*?<tr>.*?Usage:.*?<td>(.*?)[\n\s]*?<a.*?>', source.text) |
word = matchedObject.group(1) |
meaning = matchedObject.group(2) |
synonyms = matchedObject.group(3) |
usage = matchedObject.group(4) |
cleanedWord = re.sub('<.*?>', '', word) |
cleanedWord = re.sub('&#\d{2,4};', '', cleanedWord) |
cleanedWord = re.sub(' ', ' ', cleanedWord) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
cleanedSynonyms = re.sub('<.*?>', '', synonyms) |
cleanedSynonyms = re.sub('&#\d{2,4};', '', cleanedSynonyms) |
cleanedSynonyms = re.sub(' ', ' ', cleanedSynonyms) |
cleanedUsage = re.sub('<.*?>', '', usage) |
cleanedUsage = re.sub('&#\d{2,4};', '', cleanedUsage) |
cleanedUsage = re.sub(' ', ' ', cleanedUsage) |
entryForTextFile = "{}: {} Synonyms: {}. {}".format(cleanedWord, cleanedMeaning, cleanedSynonyms, cleanedUsage) |
entryForHTMLFile = "<strong>{}</strong>: {} Synonyms: {}. {}".format(cleanedWord, cleanedMeaning, cleanedSynonyms, cleanedUsage) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("- {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<li>{}</li>\n".format(entryForHTMLFile)) |
print("Fetching word of the day from Wordsmith...") |
source = requests.get(url) |
matchedObject = re.search(r'<h3>\n(.*?)\n</h3>[\S\s\n]*?<div style=".*?">MEANING:</div>[\S\s\n]*?<div style="margin-left: 20px;">\s+?([.\s\S\n]*?)</div>[.\s\S\n]*?<div.*?>USAGE:</div>[.\n\S]*?<div.*?>\s+?[.\n\S]*?([.\n\S\s]*?.*?)[\n]</div><br>[\n\s\S]*?A THOUGHT FOR TODAY:</div>[\n\s\S]*?(.*?)[\n\s\S]*?<br><br>', source.text) |
word = matchedObject.group(1) |
meaning = matchedObject.group(2) |
cleanedWord = re.sub('<.*?>', '', word) |
cleanedWord = re.sub('&#\d{2,4};', '', cleanedWord) |
cleanedWord = re.sub(' ', ' ', cleanedWord) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
entryForTextFile = "{}: {}".format(cleanedWord, cleanedMeaning) |
entryForHTMLFile = "<strong>{}</strong>: {}".format(cleanedWord, cleanedMeaning) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("- {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<li>{}</li>\n".format(entryForHTMLFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("</ul>\n\n<center><h3>PHRASE OF THE DAY</h3></center>\n") |
print("Fetching Phrase of the Day from International House Bristol...") |
source = requests.get(url) |
matchedObject = re.search(r'property="dc:title"><h2>(.*?)</h2>[\S\s\n]*?field-name-field-phrase-explanation[\S\s\n]*?<div class="field-item\seven">(.*?)</div>[\S\s\n]*?field-name-field-line-ex1-1[\S\s\n]*?field-item\seven">(.*?)</div></div></div>', source.text) |
phrase = matchedObject.group(1) |
meaning = matchedObject.group(2) |
usage = matchedObject.group(3) |
cleanedPhrase = re.sub('<.*?>', '', phrase) |
cleanedPhrase = re.sub('&#\d{2,4};', '', cleanedPhrase) |
cleanedPhrase = re.sub(' ', ' ', cleanedPhrase) |
cleanedMeaning = re.sub('<.*?>', '', meaning) |
cleanedMeaning = re.sub('&#\d{2,4};', '', cleanedMeaning) |
cleanedMeaning = re.sub(' ', ' ', cleanedMeaning) |
cleanedUsage = re.sub('<.*?>', '', usage) |
cleanedUsage = re.sub('&#\d{2,4};', '', cleanedUsage) |
cleanedUsage = re.sub(' ', ' ', cleanedUsage) |
entryForTextFile = "{}: {} {}".format(cleanedPhrase, cleanedMeaning, cleanedUsage) |
entryForHTMLFile = "<p><strong>{}</strong>: {} {}</p>\n\n".format(cleanedPhrase, cleanedMeaning, cleanedUsage) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("PHRASE OF THE DAY - {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("{}".format(entryForHTMLFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<center><h3>THOUGHT FOR TODAY</h3></center>\n") |
print("Fetching Thought for the Day from Wordsmith...") |
source = requests.get(url) |
matchedObject = re.search(r'<h3>\n.*?\n</h3>[\S\s\n]*?<div style=".*?">MEANING:</div>[\S\s\n]*?<div style="margin-left: 20px;">[.\s\S\n]*?</div>[.\s\S\n]*?<div.*?>USAGE:</div>[.\n\S]*?<div.*?>[.\n\S]*?[.\n\S\s]*?.*?[\n]</div><br>[\n\s\S]*?A THOUGHT FOR TODAY:</div>\s+?(.*?[\n\s\S]*?)<br><br>', source.text) |
thought = matchedObject.group(1) |
entry = "".format(thought) |
cleanedThought = re.sub('<.*?>', '', thought) |
cleanedThought = re.sub('&#\d{2,4};', '', cleanedThought) |
cleanedThought = re.sub(' ', ' ', cleanedThought) |
entryForTextFile = "{}".format(cleanedThought) |
entryForHTMLFile = "{}".format(cleanedThought) |
with open(pathToTXTfile, 'a') as fileHandler: |
fileHandler.write("\nTHOUGHT FOR TODAY - {}\n".format(entryForTextFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("<p>{}</p>\n".format(entryForHTMLFile)) |
with open(pathToHTMLfile, 'a') as fileHandler: |
fileHandler.write("</div>\n\n</body>\n\n</html>") |
with open(pathToTXTfile, 'r') as fileHandler: |
contents = fileHandler.read() |
with open(pathToArchiveFile, 'a') as fileHandler: |
fileHandler.write("{}".format(contents)) |
print("Opening files and containing directory.") |
webbrowser.open(pathToTXTfile) |
webbrowser.open(pathToArchiveFile) |
webbrowser.open(pathToHTMLfile) |
subprocess.Popen(['explorer', locationOfYourScript]) |
Executing the script
Paste the above contents in a .py file on your computer. In the terminal or command prompt, type in $python path_to_script.py to execute the script. If all goes well, the script will open the text files, HTML file and the containing directory for you once it is done scraping.
In Windows, you can optionally execute a batch file (.bat), lying in the same directory as the .py file, with the following contents, to get the output.
python "%~dp0name_of_script.py" |
You can schedule this script to run daily using Windows Task Scheduler. A demonstration is given here.
See also:







